I recently completed a workshop both in code form on Github and recorded on YouTube for the University Consortium for GIS, 2021 Symposium. We learn how to develop a geospatial risk prediction model – a type of machine learning model, specifically to predict fire risk in San Francisco, California.
This workshop is an abridged version of Chapter 5 on Predictive Policing found in a new book, Public Policy Analytics by Ken Steif. The book is published by CRC Press, but is also available as open source.
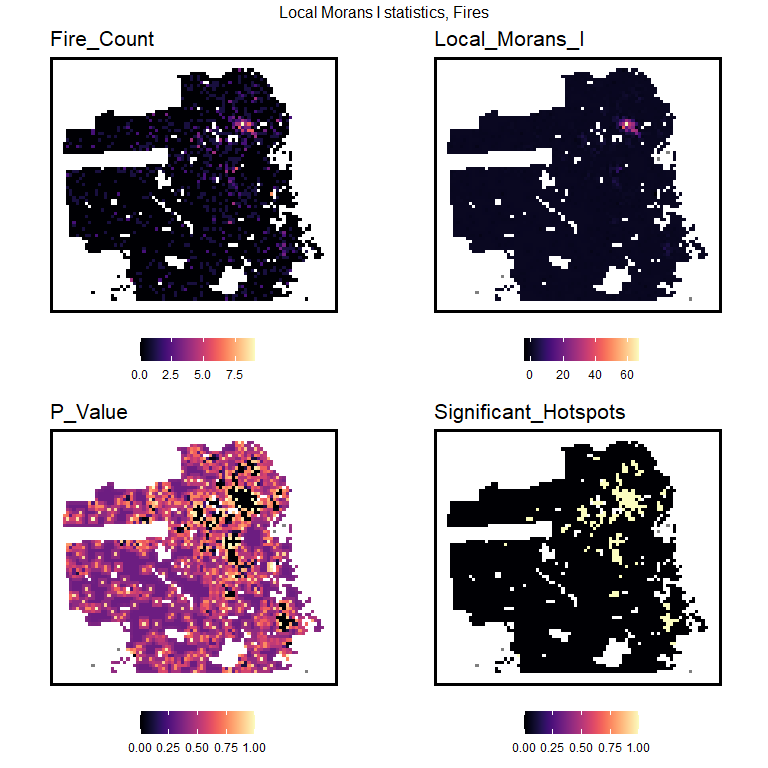
Here we posit that fire risk across space is a function of exposure to nearby spatial risk or protective factors, like blight or aging infrastructure. These algorithms are explicitly spatial in nature because of their reliance on measuring geographic exposure.
These models provide intelligence beyond points on a map – that simply tell us to revisit past locations of adverse events. They provide a more thorough predictive understanding of spatial systems and why things occur where.
Fire is a relatively rare event, and the ‘latent risk’ for fire is much greater than the number of fires actually observed. Today, we will estimate this spatial latent risk to help the San Francisco Fire Department do operational planning, like fire inspection and smoke detector outreach.
Please check out the accompanying video for a lot more context on fire prediction and algorithmic bias. Minimal context is provided here.
This tutorial assumes the reader is familiar with spatial analysis and data wrangling in R – namely the sf and tidyverse packages. It is also assumed the reader has some familiarity with machine learning.