Ken Steif, Ph.D
Sydney Goldstein, M.C.P
Check out the full report and codebase here.
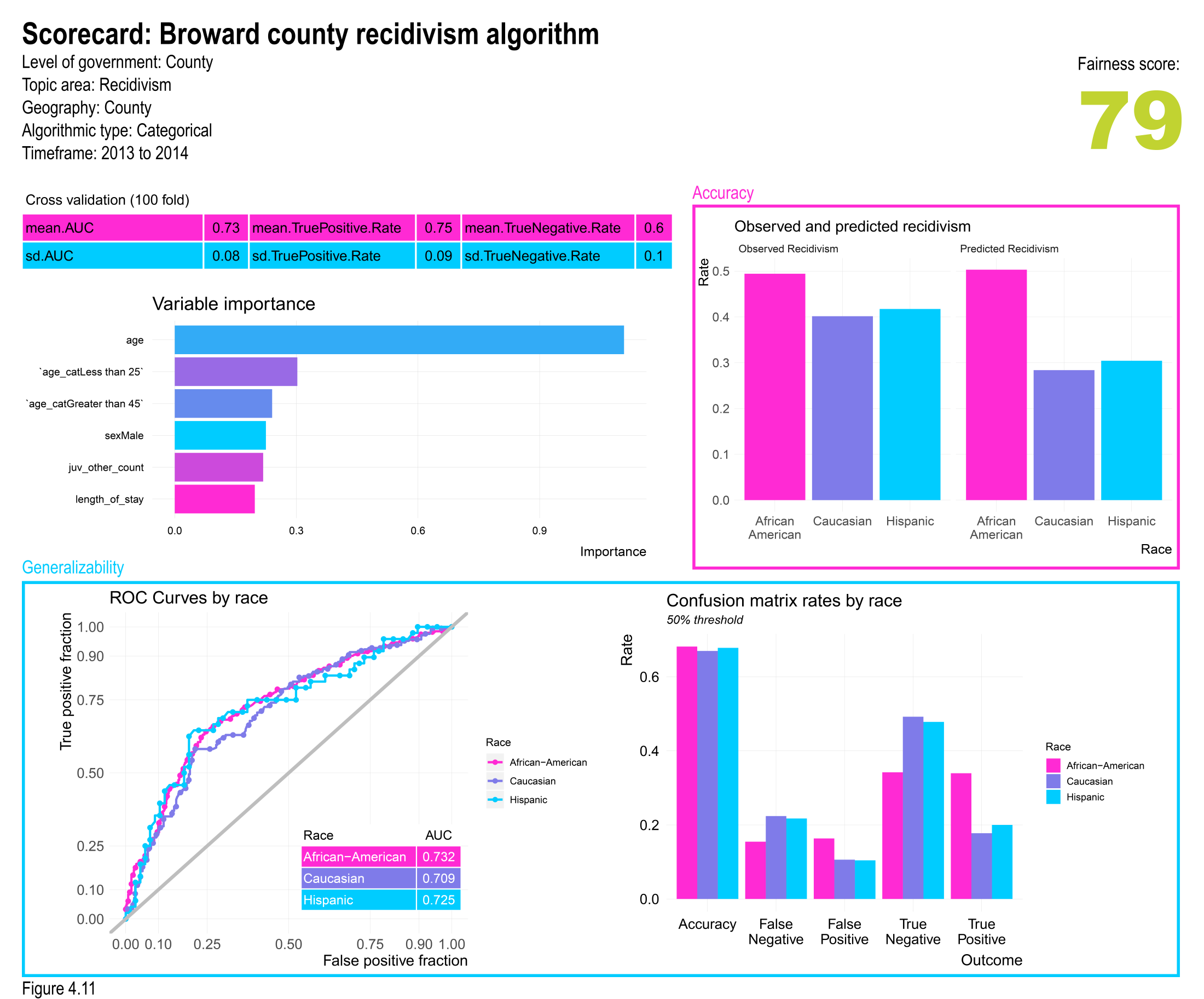
In the Spring of 2016, ProPublica published an investigation of a ‘risk assessment’ algorithm developed by a private company to help governments make criminal justice decisions. Their investigation revealed systematic racial disparities in the algorithm’s predictions that if used to make decisions, could lead to discrimination.
The ProPublica piece generated a host of scholarly interest among computer scientists and criminologists who began opening the algorithm’s ‘black box’ in an attempt to discover the source of discrimination. This work revealed that when algorithms are trained on data from historically disenfranchized communities, including those subjected to systematic over-policing, their predictions may inevitably be biased.
Algorithms have already transformed how the private-sector does business and are beginning to take root in government. Unlike business, government has a responsibility to be transparent about how algorithms inform resource allocation decisions.
The goal of this project is to develop a primer that enables policy makers and government data scientists to evaluate their own algorithms for bias. Context is provided as well as replicable code for two common public-sector algorithmic use cases. There are four significant contributions of the report:
1. Describe disparate impact in an algorithmic context.
Disparate impact is the notion that although a program or practice may not be discriminatory on its face, it may still have unintended discriminatory consequences. For both example use cases, we show how biased predictions can lead to greater social costs for one protected group compared to another.
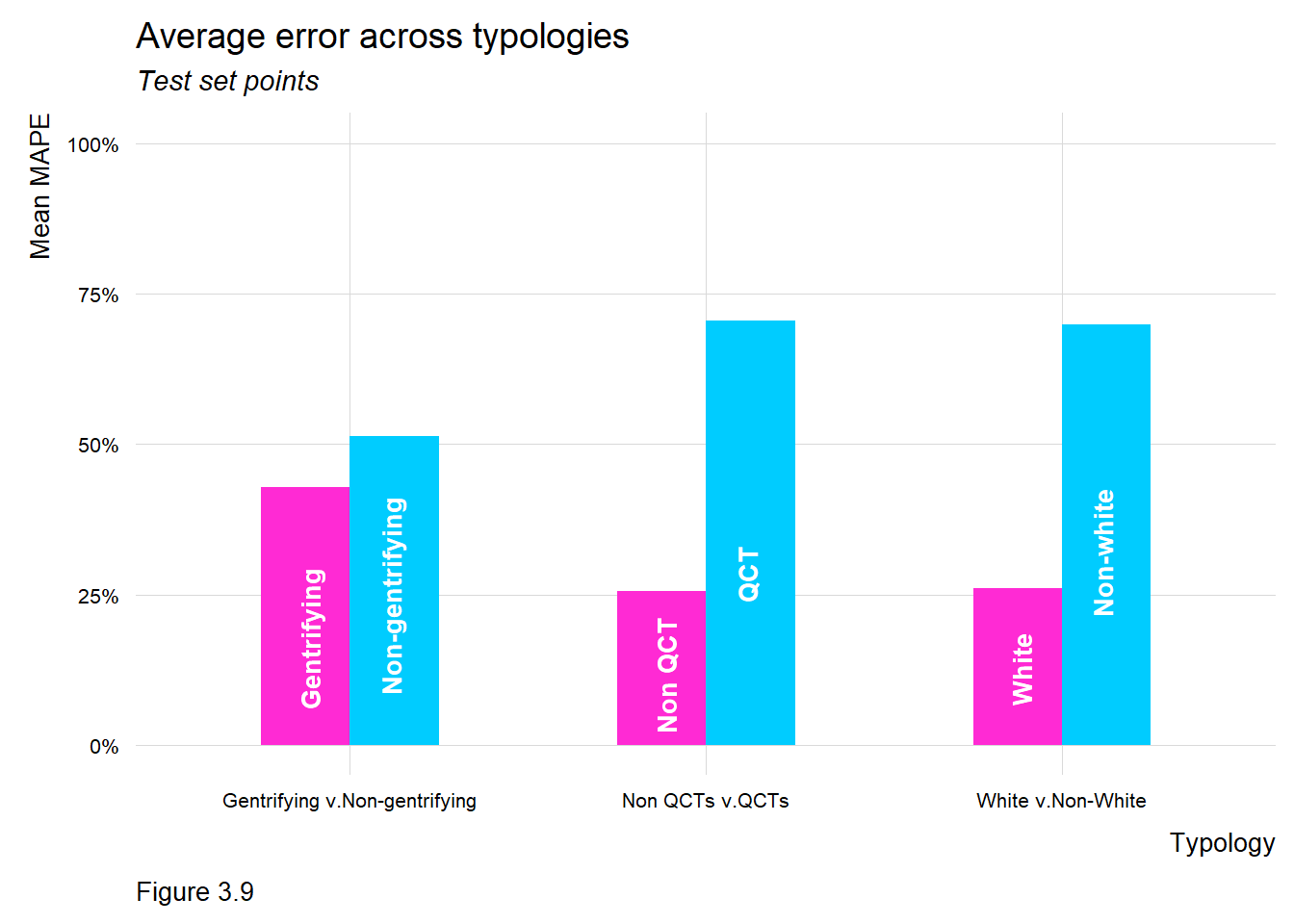
The first use case explores the standard algorithm used by many counties to predict home values and set property taxes. As the image above illustrates, we find that households in predominately non-white neighborhoods are subject to relatively higher predictive error rates. If such an algorithm were to be used for tax assessment, it would, “place a disproportionately higher tax burden on lower-valued homes”, and could have a disparate impact on communities of color who already experience higher rates of housing instability.
2. Provide fairness metrics related to accuracy & racial generalizability.
We provide a framework for evaluating the extent to which an algorithm is not only accurate (ie. the rate of correct predictions), but generalizes equally well across different groups.
In its investigation, ProPublica suggests that a recidivism algorithm can be both fair and unfair, simultaneously. Although an algorithm may predict recidivism across races with comparable accuracy, there may be important differences in the kinds of errors that it generates.
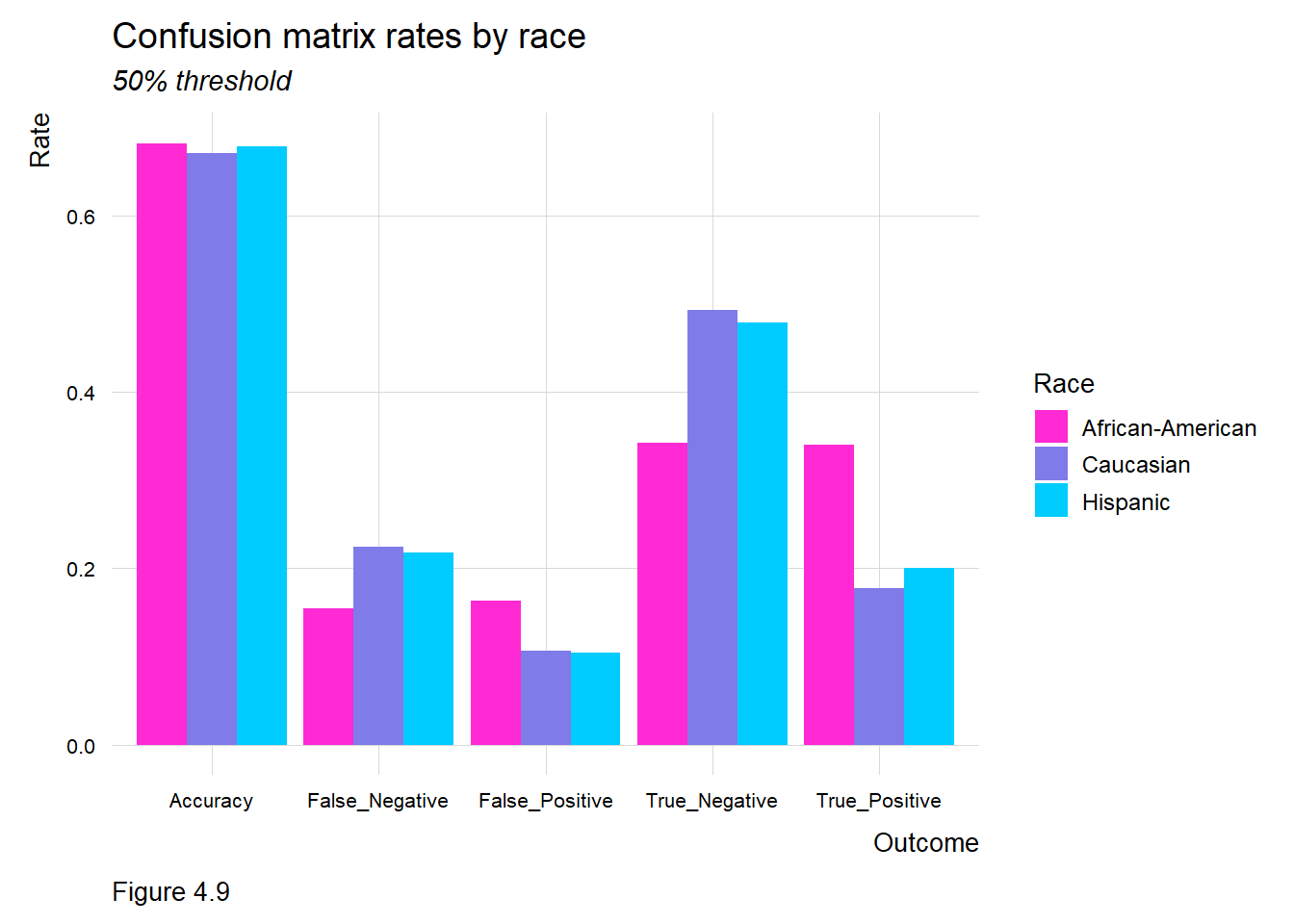
The image above illustrates an algorithm with higher False Positive rates and lower False Negative rates for African Americans and Caucasians, respectively. In practice, this means that a higher proportion of African Americans are predicted to recidivate but don’t, while a higher rate of Caucasians are predicted not to recidivate but do. The social costs related to the first outcome are apparent, as are the public safety implications of the second. Our framework suggests several standardized metrics for ensuring algorithms generalize across protected groups.
3. Provide code examples that government data scientists can learn from.
Most of the innovation in this realm has been driven by scholars, their work highly conceptual and locked behind journal paywalls. Meanwhile, governments continue to deploy all manner of algorithms to distribute subsidies, determine program eligibility and allocate limited taxpayer resources.
We think our primary contribution is providing beginner level #rstats code enabling government data scientists to replicate our work and learn how to evaluate their own algorithms. The appendix of the report includes the codebase, and all of the Open Data we use.
4. Pitch a ‘Scorecard’ standard to compare across government algorithms.
Given that discrimination is omnipresent throughout the history of American government, it would not be surprising to find that many government algorithms exhibit some measure of bias. In response, policy makers must develop domain-specific protocols to ensure that data-driven decisions are equitable.
As part of this, stakeholders will need to compare their algorithms to those of their peers. Further, elected officials, policy makers, service providers and citizens will all demand the appropriate level of transparency.
To provide this transparency, we suggest an open source repository of algorithmic ‘scorecards’, each featuring a standardized set of metrics and categorized such that stakeholders can compare and contrast. The first image above is an example of such a scorecard. In the report we provide further motivation:
- All jurisdictions at the local, state, and Federal levels collect comparable administrative data to determine program eligibility as well as to develop budgets and strategic plans.
- All jurisdictions share a comparable set of algorithmic use cases, each of which can be realized by leveraging these administrative datasets.
- Thus, in the future, all jurisdictions will be developing comparable algorithms that predict comparable outcomes of interest towards the fulfillment of these shared use cases.
We hope you take a look at the report and maybe try to replicate our models. Algorithmic fairness will be an important issue in our lives for decades to come. The sooner we develop a shared understanding of bias, the sooner we can ensure the benefits of these tools outweigh their costs.
Ken Steif, PhD is the founder of Urban Spatial. You can follow him on Twitter @KenSteif. For those interested in learning these methods, you may consider working with Ken directly by applying to the Master of Urban Spatial Analytics program at the University of Pennsylvania.
This work would not have been possible without the generous support of Dyann Daley and Predict Align Prevent; as well as several reviewers including Drs. Dennis Culhane, Dyann Daley, John Landis, and Tony Smith. We also greatly appreciate the time and effort of Matt Harris, who ensured our code is replicable.