Problem Statement: Can we make bike share strategic planning more efficient and effective for smaller cities and communities?
Proposed Solution: Combining predictive modeling and web-based GIS into a ‘planning support system’ can help democratize the planning process by providing online empirical tools free of charge to smaller communities.
Research Question: In cities with bike share systems, are ridership patterns sufficiently general enough that they can be used to predict bike share usage in cities without such systems?
Training Set: Take data from these bike share systems:

Test Set: …and use them to predict the count of bike share trips in Philadelphia
![]()
The most important consideration is that our predictions are generalizable – that they can be used across a diverse set of urban contexts.
The idea is to train a statistical model on a series of spatial factors that help predict variation in the number of bike share trips across a set of neighborhoods. We then “test” the extent to which the predictions are applicable to a city without bike share – like Philadelphia.
Because no one has a crystal ball, the interest is in making predictions across space, not time.
How do we collect the appropriate ‘training set’ data?
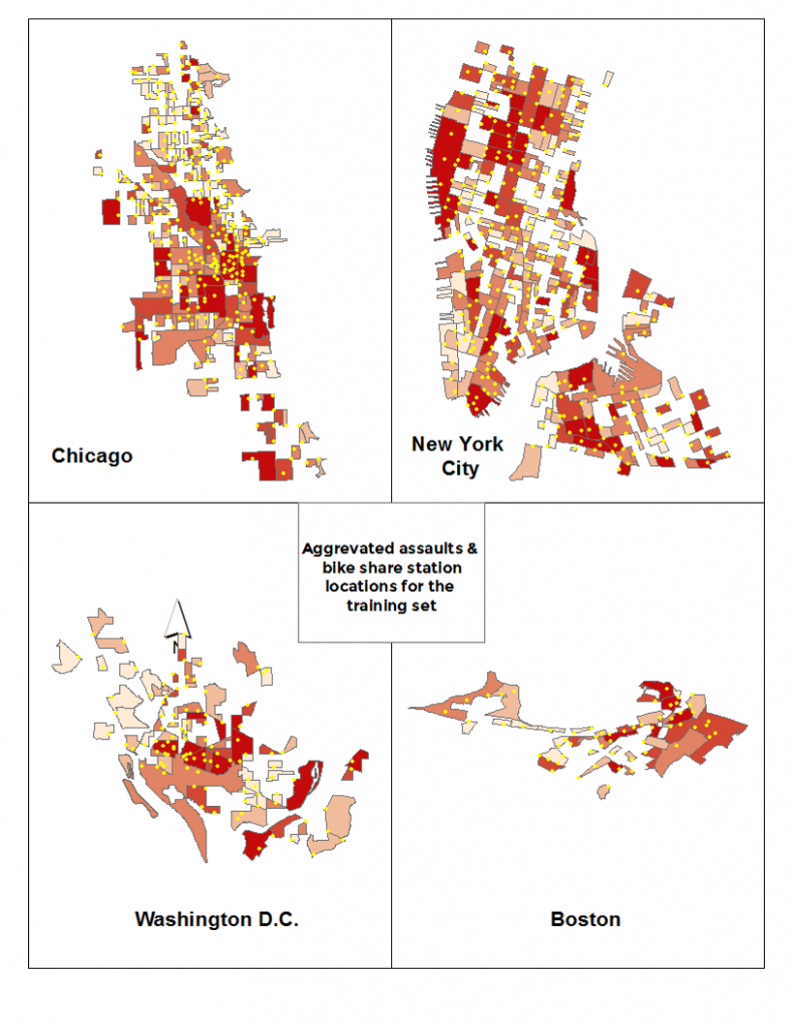
Aggravated assaults & bike share station locations by census block group
We begin by gathering a modest number of variables from various city open data websites. The image above shows the number of aggravated assaults with bike share stations overlaid atop each of the four ‘training set’ cities. The table below describes each of the variables used for the analysis. ‘strtTrip’ is the variable to be predicted. It is the total number of bike share departures by census block group for the first four months of each city’s bike share system.
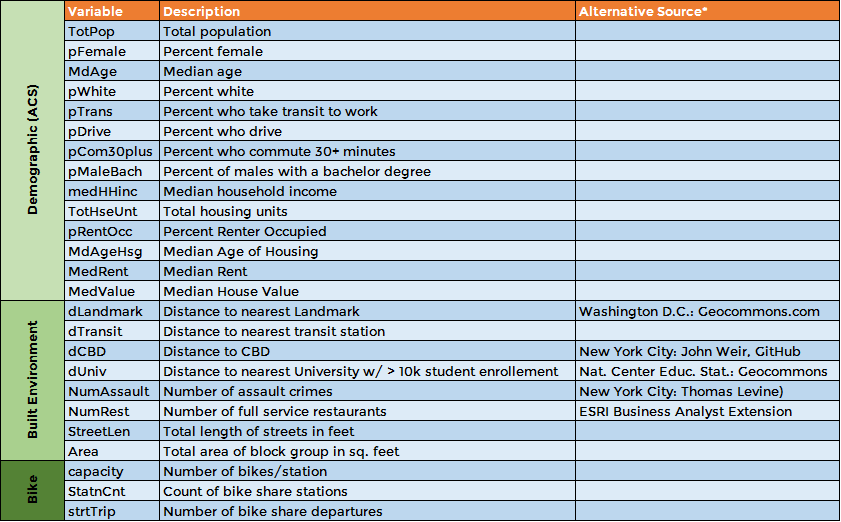
Variables used in the analysis
Do the variables generalize to one unique urban context?
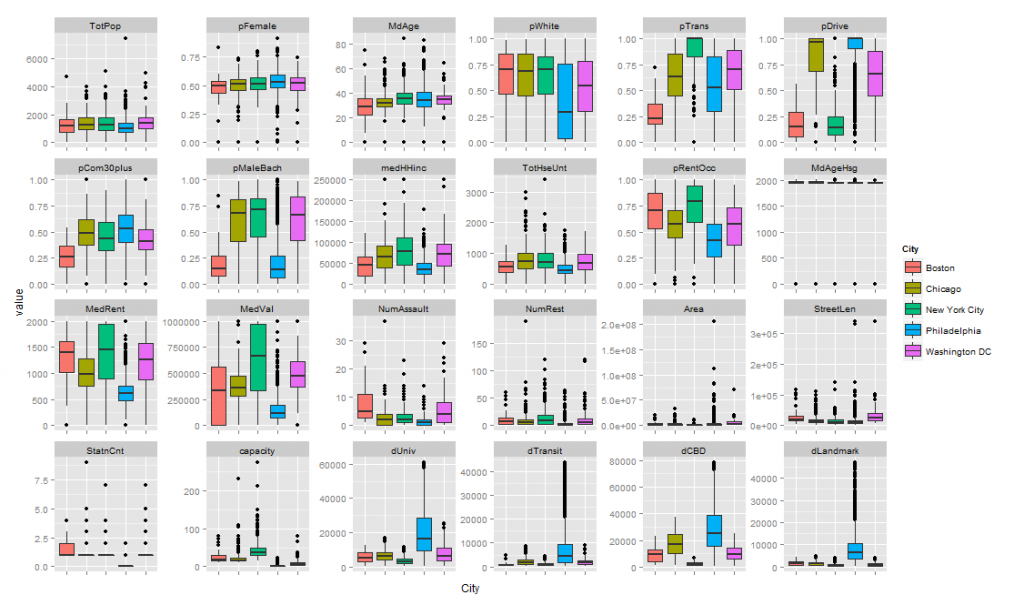
Box plot of predictor variables used in the analysis
Here are those ‘training set’ variables visualized in box plot form by city. Notice how a variable like ‘pFemale’ or percent female seems to be distributed similarly across each of the cities used in the analysis. This suggests that this variable is generalizable across the different urban contexts that comprise our ‘training set’. By contrast, ‘pDrive’ or percent who commute to work by automobile may not be.
How do we collect the appropriate ‘test set’ data?
This analysis was undertaken ~9 months before the debut of bike share in Philly. At that time, there was no exact information about where and how many bikes would be allocated in a given area. All that was available was pdf documents prepared by foundation funded planners in Philadelphia. Pdf maps of ‘bike share zones’ were digitized in a GIS and corresponding information on the number of stations and bikes per zone were used to ‘simulate’ the placement of stations and bikes within the study area.
This moves the analysis in a direction that more closely resembles the strategic planning process that a community at the early stages of system planning might undertake.
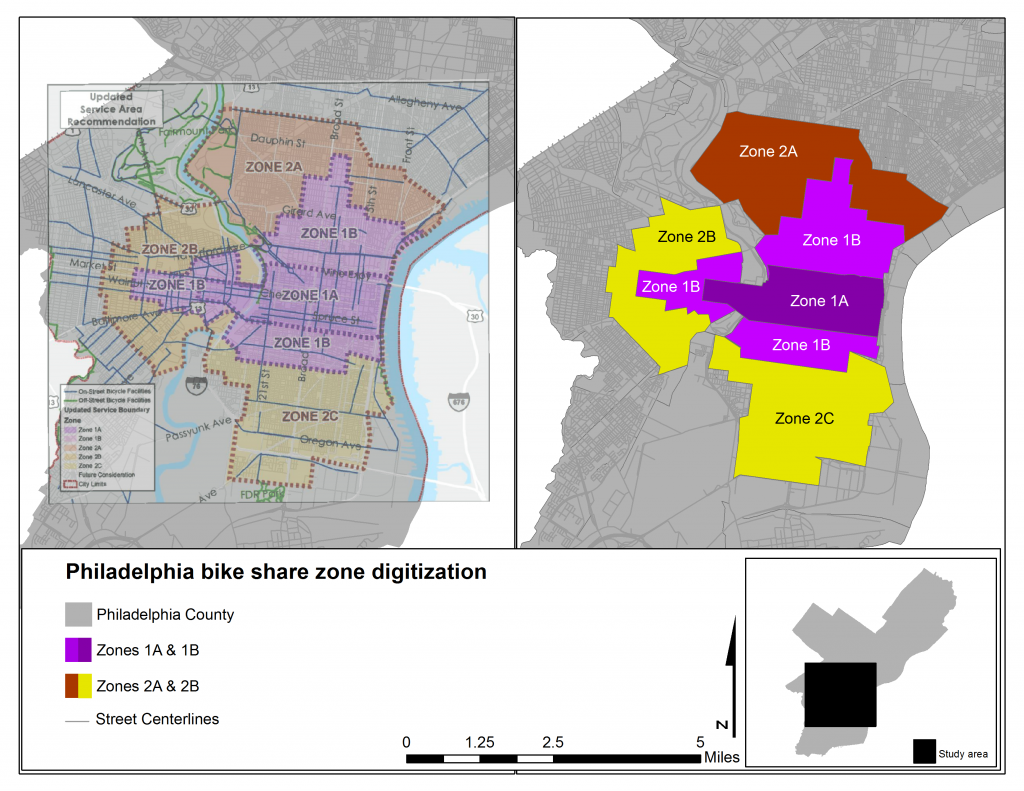
GIS digitization of proposed ‘bike share zones’ in Philadelphia
Constructing the predictive model
When developing the actual predictive model, the most important consideration is that the model performs well in an ‘out of sample context’. Keep in mind that the analysis was originally undertaken long before the Philly bike share system began. Thus the best way to test how well the model would work for a system that has yet to open their bike share system is to test the model in an out of sample context. We do this by way of cross-validation.
We also use cross-validation to discern which variables from our four training set cities best explain bike share trips. Finally, we estimated many different models across three separate types of predictive algorithms – Linear Regression (OLS), Random Forest and Gradient Boosting. The predictions range considerably depending on the algorithm used.
Analyzing the predictions
The table below shows the predicted count of bike share trips in Philadelphia according to the three predictive algorithms we used. We then display the geographic extent of the predictions in Philadelphia.

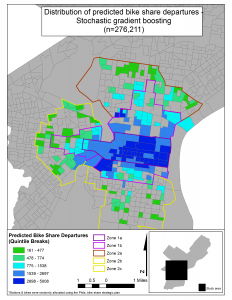
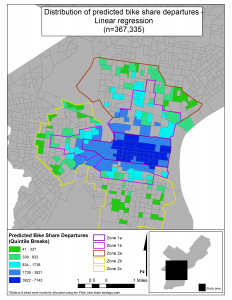
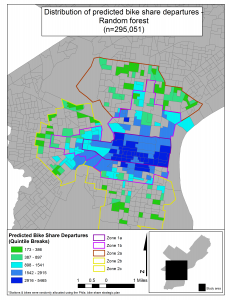
The spatial distribution of predicted bike share trips in Philadelphia

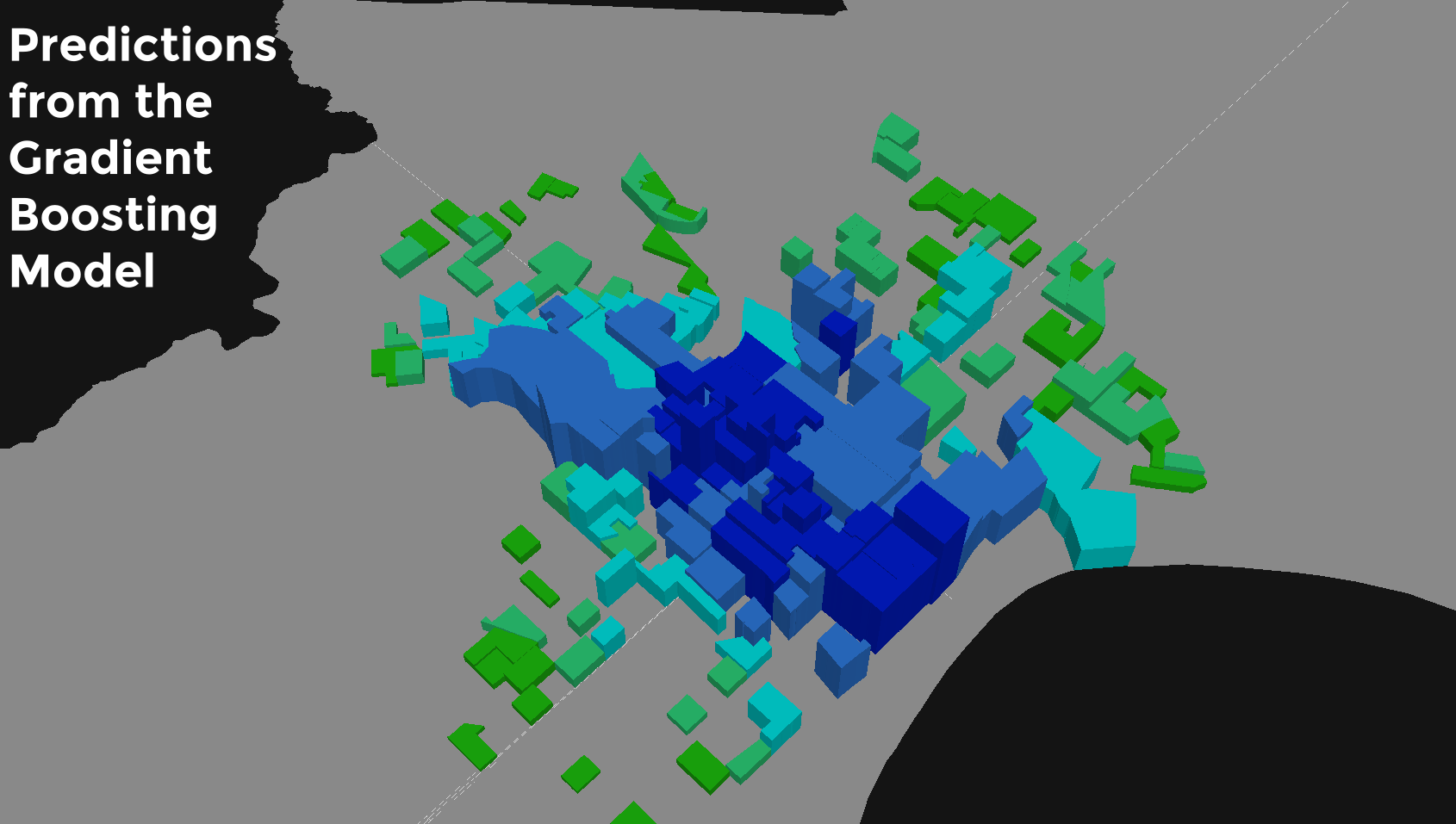
Of the three predictive algorithms, the gradient boosting routine is best able to deal with the (non-linear) local spatial nuance of bike share departures across the four training set cities.
This model predicts 267,211 trips in the first 4 months of Philadelphia’s bike share system. Now that it has been more than 4 months since Philadelphia’s system debuted, we know that the model predicts just 17% more trips than actually occurred.
This is an incredibly strong error rate particularly given that the model was trained on just four cities with minimal feature engineering.
This is even more exciting given that of the nearly 5 million bike share trips used to generate these predictions, 76% of those come from New York City – an urban context certainly unto itself. Despite this and despite the fact that the Philadelphia station locations were simulated, the model is still able to make very accurate predictions.
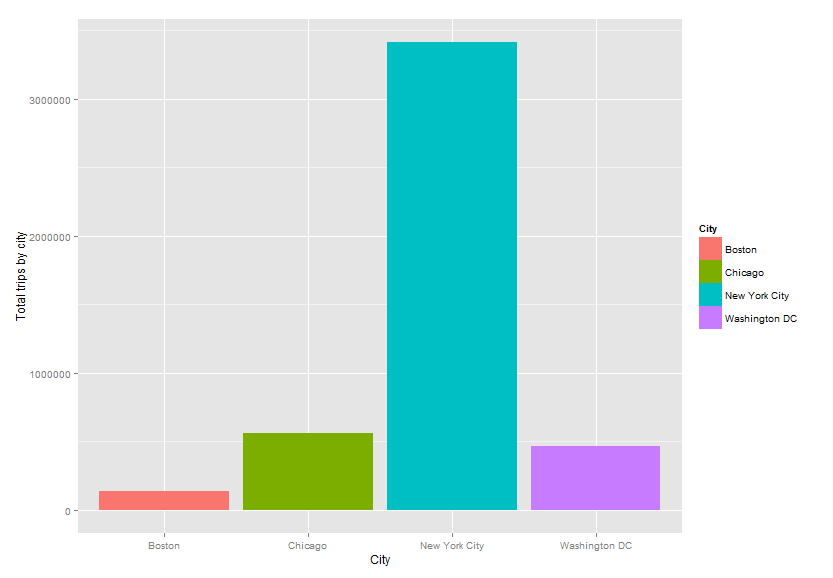
Total number of bike share trips by city used in the analysis
So how does this analysis make us smarter about how we plan bike share systems?
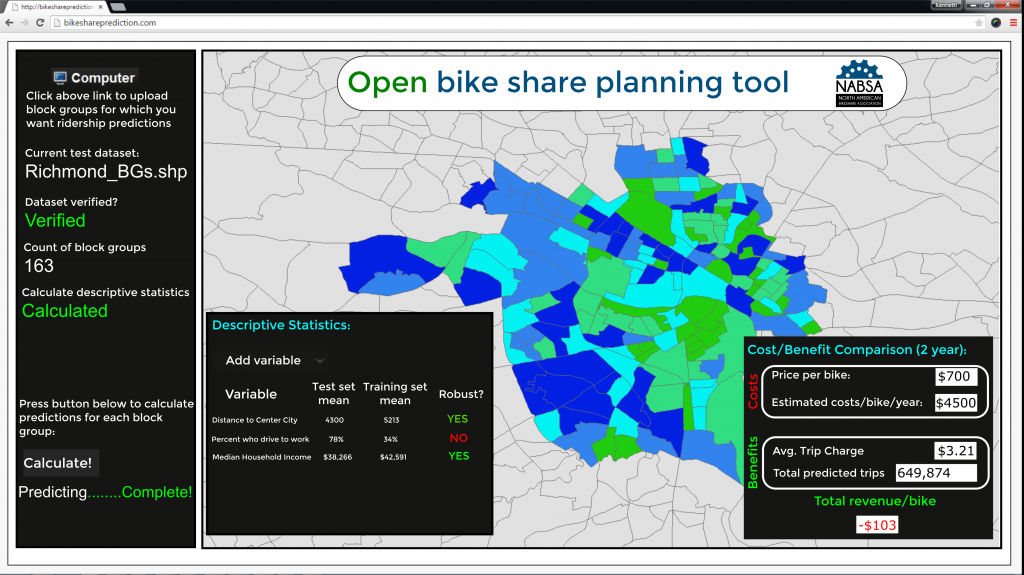
Let’s democratize the planning process by placing these powerful empirical tools into the hands of smaller communities for free to help them plan their own systems
The above (mock) web site would give smaller communities a free tool that could inform planners, based on the experience in other cities (the predictions), if the benefits of bike share in their cities outweigh the costs.
The workflow would be as follows:
- Planners, non-profits, city officials or even students could compile the requisite open data in a GIS system and upload the GIS shapefile onto the site.
- The site would verify that the data is formatted correctly and then provide a series of descriptive statistics that inform the user whether the predictive model is generalizable to their city.
- The site would then “stamp” each census block group with the predicted number of trips and allow the user to visualize the spatial distribution of trips.
- The site would then allow the user to conduct a simple cost/benefit evaluation.
- The value-added benefit of this tool, is if the numbers do not add up, the user can reconfigure the proposed system setup and then re-upload a new version of the data. This allows an incredibly simple and free solution from which planners can do scenario planning.
This web-based ‘planning support system’ would allow communities with little technical expertise to create actionable intelligence to help them better allocate their limited resources across space.
Let’s go back to the research question:
In cities with bike share systems, are ridership patterns sufficiently general enough that they can be used to predict bike share usage in cities without such systems?
Yes
Why does the predictive model work so well? Because it turns out that bike share users across the four training set cities share similar ‘demand-side’ characteristics. What the model is really good at is accounting for the many ‘supply-side’ differences across cities like the locations of tourist sites and hotels.
Future work would be aimed at lowering the error rate. To do this, we would need more data from more cities. A more sophisticated feature engineering process would also help us move toward a more robust predictive model.